Algorithms#
Basic Algorithm#
Basic search is a brute force search that moves through every element of the string until it finds an instance of the key. The algorithm starts by aligning the first element of the key to the first element of the text. At each position of the string, the algorithm checks to see if the elements match. If the elements match for the length of the key, the algorithm has found a match. Otherwise, it moves to the next element in the string to compare it to the key once again. This process repeats until all of the instances of the key have been found.

Upside: This method has some upsides. It is extremely reliable, and easy to implement.
Downside: Since it makes a comparison at each element in the string, and does not reposition when a mismatch is found, it is very inefficient for large strings and/or keys. These negatives are so severe that it really is only used as a learning tool for people new to algorithms in general.
KMP(Knuth Morris Pratt)#
The Knuth-Morris-Pratt (KMP) algorithm optimizes string matching by utilizing a Longest Prefix Suffix (LPS) table, which is a preprocessed array indicating the length of the longest proper prefix that is also a suffix for each position in the key. The LPS table efficiently guides the search process, allowing the algorithm to skip unnecessary comparisons when a mismatch occurs. The preprocessing algorithm initializes the LPS table by iteratively comparing characters in the key and updating the table accordingly. During the search phase, KMP compares the key to the string while intelligently skipping elements based on the LPS values, significantly reducing the number of comparisons compared to a basic approach
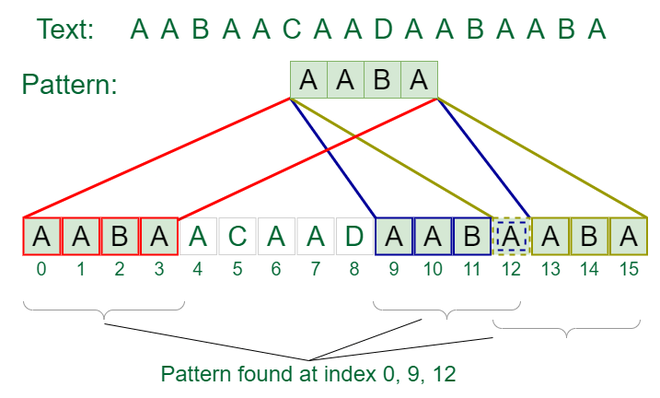
Upside: In essence, KMP enhances the efficiency of string matching by strategically considering the inherent patterns within the key.
Downside: it is not the most efficient search algorithm in our project.
Boyer Moore#
This algorithm employs two efficient preprocessing methods: the Bad Character Heuristic and the Good Suffix Heuristic. The Bad Character Heuristic focuses on handling mismatches by shifting the key strategically to the last instance of the “bad character” found in the string. If the bad character isn’t present in the key, the comparison window is moved to the character following the bad character, avoiding unnecessary comparisons. The bad character array, sized for all ASCII values,facilitates this process by storing the rightmost occurrences of characters in the key. On the other hand, the Good Suffix Heuristic also addresses mismatches by recording the character following the mismatched one, known as the good suffix. It then locates the next instance of the good suffix in the string, comparing only the characters preceding it in both the string and the key. The good suffix array guides this process, indicating the number of characters to skip to check for the good suffix in the string. The Boyer-Moore algorithm intelligently combines the insights from both heuristics, optimizing the shift of the comparison window based on the greater value derived from the Bad Character and Good Suffix Heuristics.

Upside: This approach minimizes unnecessary comparisons, enhancing the efficiency of string search operations.